How I Built an AI Curator to Enhance my Book Highlights
One of my favorite apps is Readwise. It sends me an email every day with five of my Kindle highlights. It is an amazing way to retain knowledge from the books I read. However, when reading my daily highlights, I often find myself looking up more information. Sometimes, I've read books too long ago to understand the context of the highlight, or a specific interest is triggered that leads into a rabbit hole full of new knowledge.

What if I could use an LLM to automatically add this context to the highlight?
If I feed the highlight to an LLM, it should be able to generate or find a lot of interesting information. For example, the larger historical or scientific context, relevant locations, or related Wikipedia articles. So I set out to see if I could build it.
My idea was to create an app that provides a new highlight every day with additional interesting information added to it by an LLM and different third-party APIs.
Despite not being a traditional software developer, I was able to build this app from scratch in Swift thanks to Claude and its projects feature. I did some initial design explorations in Figma but very quickly moved to prototyping directly in code.
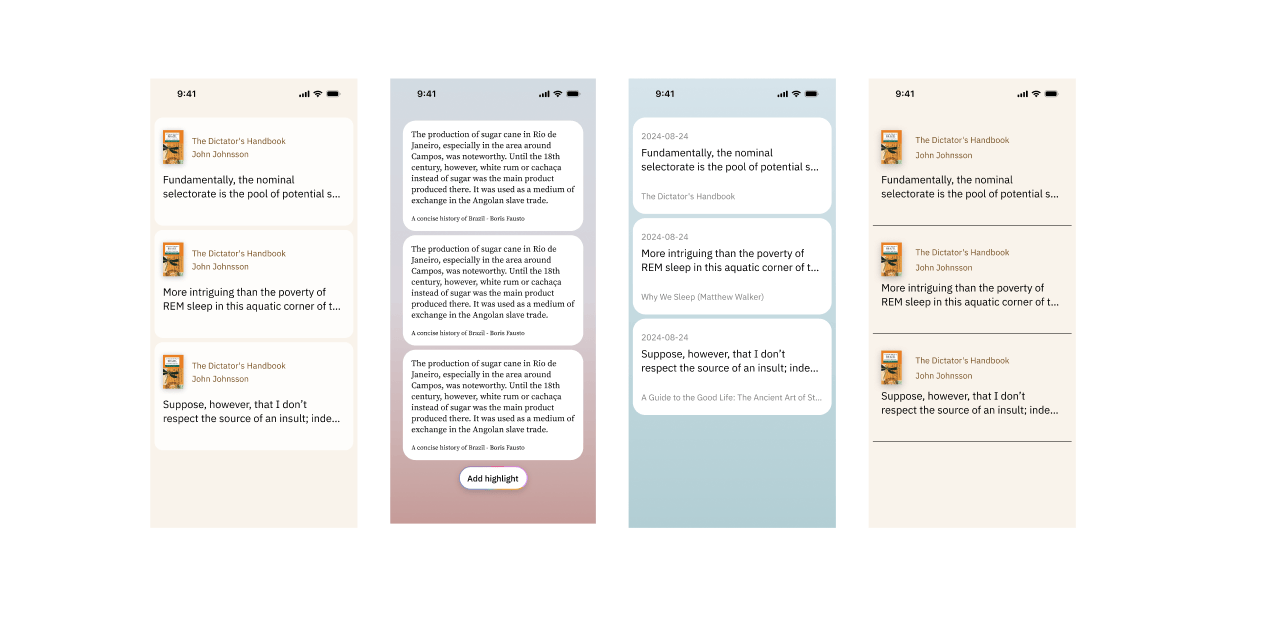
For the first version, I fed the app the text file with the highlights. When creating a new highlight page, the app goes through a number of steps:
- Find a random highlight and check if it has been used before
- Create a JSON file using a specific template and add the highlight
- Parse the highlight and send the book title to the Google Books API to get the full title, author, and book cover
- From the book cover, extract the average color and use it as the background of the header
-
Send the highlight to ChatGPT with the following prompt:
let messages = [ ["role": "system", "content": "You are an AI assistant that enhances book highlights with additional context and information."], ["role": "user", "content": """ Given the following book highlight, generate additional information: Highlight: "\(highlight)" Book: "\(book)" Date: \(date) Provide a JSON response with the following fields: - title: THIS FIELD IS REQUIRED. A title for this highlight - geocode: THIS FIELD IS REQUIRED. Check the highlight for a relevant location. If a relevant location is mentioned, or in the larger context, a location would be helpful, add the latitude and longitude of the location. If not, respond with a latitude and longitude of 0 - location: the name of the location that you added. - tags: THIS FIELD IS REQUIRED. Create an array of maximum 3 relevant tags based on the highlight. - biggerPicture: THIS FIELD IS REQUIRED. Help the reader understand the highlight by placing it in a larger historical, societal, and or scientific context. Keep the content to one paragraph, keep it concise and easy to read. - relatedQuestions: THIS FIELD IS REQUIRED. Based on the highlight, imagine what follow up questions the reader may have. These could be about the context of the highlight, or events,terms,locations,people, etc mentioned in the highlight. Create one to three questions and keep them short and easy to read. - wikiQuery: THIS FIELD IS REQUIRED. based on this content, the wikipedia API will be called to return relevant articles. Make sure to extract the relevant content, topics, and other information to ensure that the Wikipedia API can return up to 3 of the most relevant related wikipedia articles. Keep it concise, only mention key terms, do not halucinate. """] ]
This resulted in the first version of the app. For each highlight, ChatGPT adds the larger context, extracts the location if relevant, and adds three follow-up questions that open a chat. It also prepares the API query for Wikipedia so that a maximum of three relevant articles are returned.
After using this version for a couple of days, it validated my idea that this is something an LLM can help with and I would enjoy using. I discovered a couple of main improvements for the second iteration:
- How to spark interest and create variety every day?
- How to deal with the accuracy of generated content?
- How to notify the user every day in a non-intrusive way?
How to spark interest every day
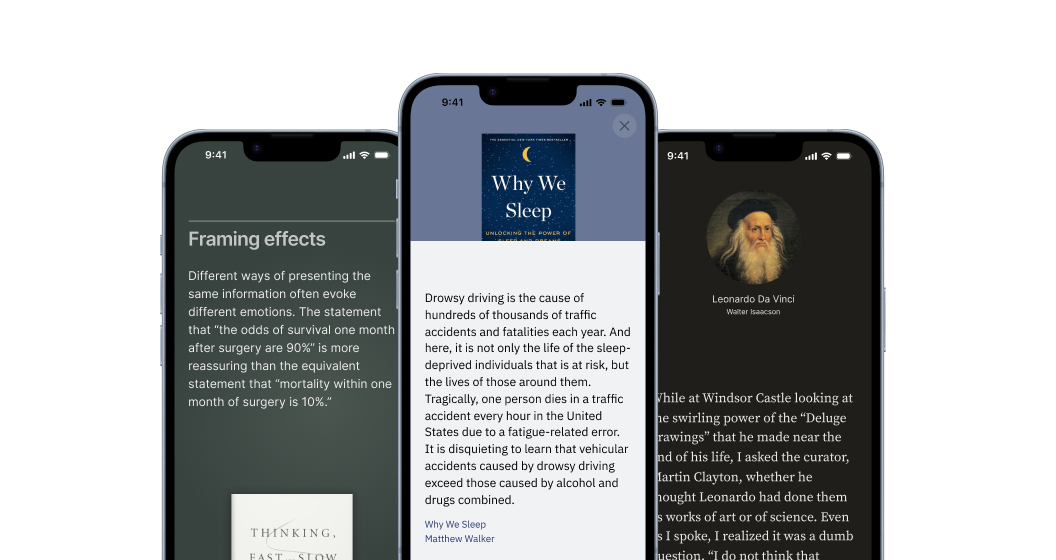
The UI is too stale. I want every day to be a little surprize. Much like how a beautiful magazine has a different look within a uniform brand identity, I want each highlight page to look unique. As an example, I created mockup as a stretch goal in Figma:
To achieve this, I made a couple of changes to the app. First, I created three distinct templates: a serious one, a playful one, and a minimal one. As part of the highlight creation process, ChatGPT will match the highlight to a template. I expanded the function that generates the colors based on the book cover to supply a wide range of colors for the templates. Now, every highlight will look different and I can scale it to include many more templates.
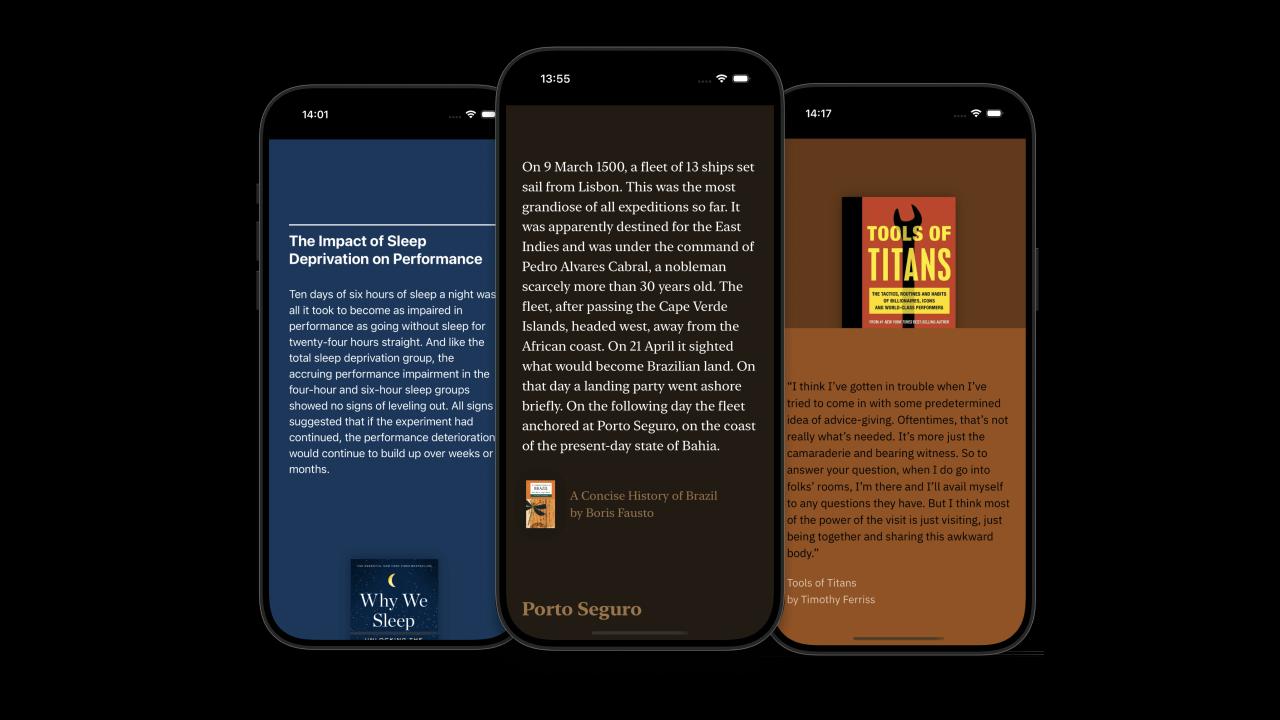
Next, I added more sources. I improved the map view by linking to the Wikipedia article of the specific location and providing the introduction. Additionally, I added the images in the Wikipedia article to the map view.
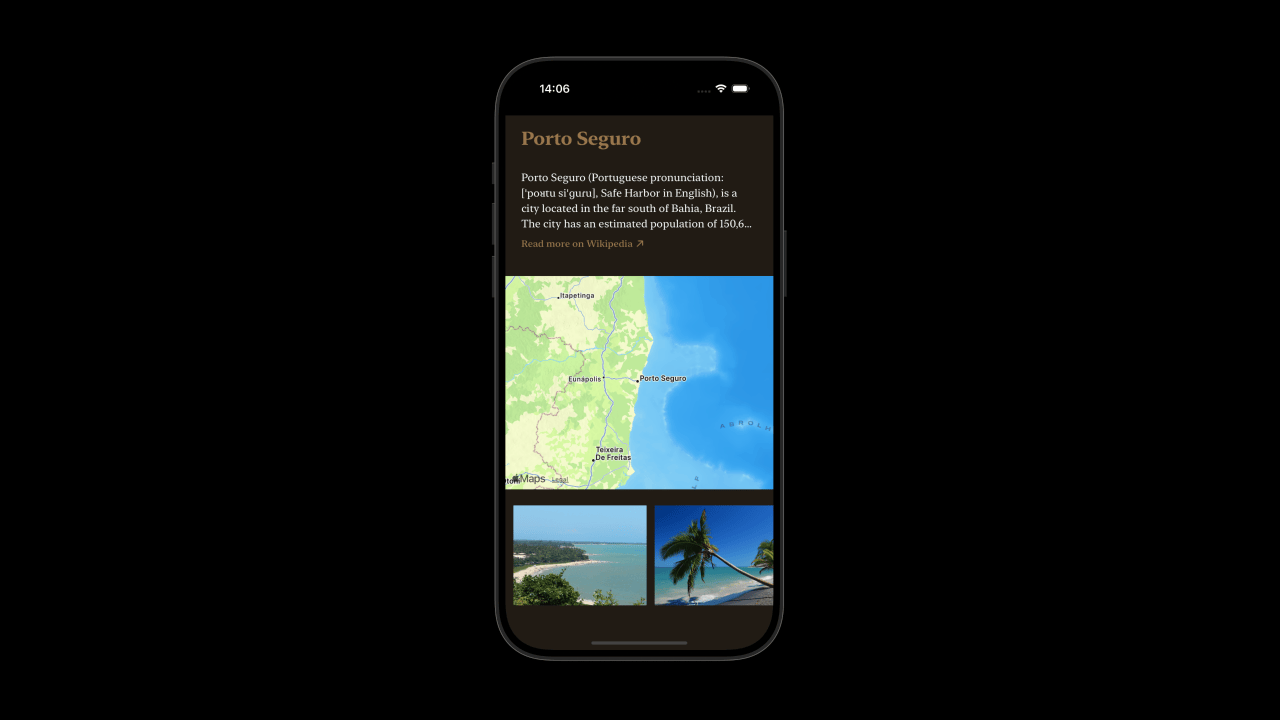
I also added API calls to Apple Podcasts and YouTube to add relevant videos and podcasts. Just like with Wikipedia, I use ChatGPT to prepare the API queries in order to get the most relevant results.
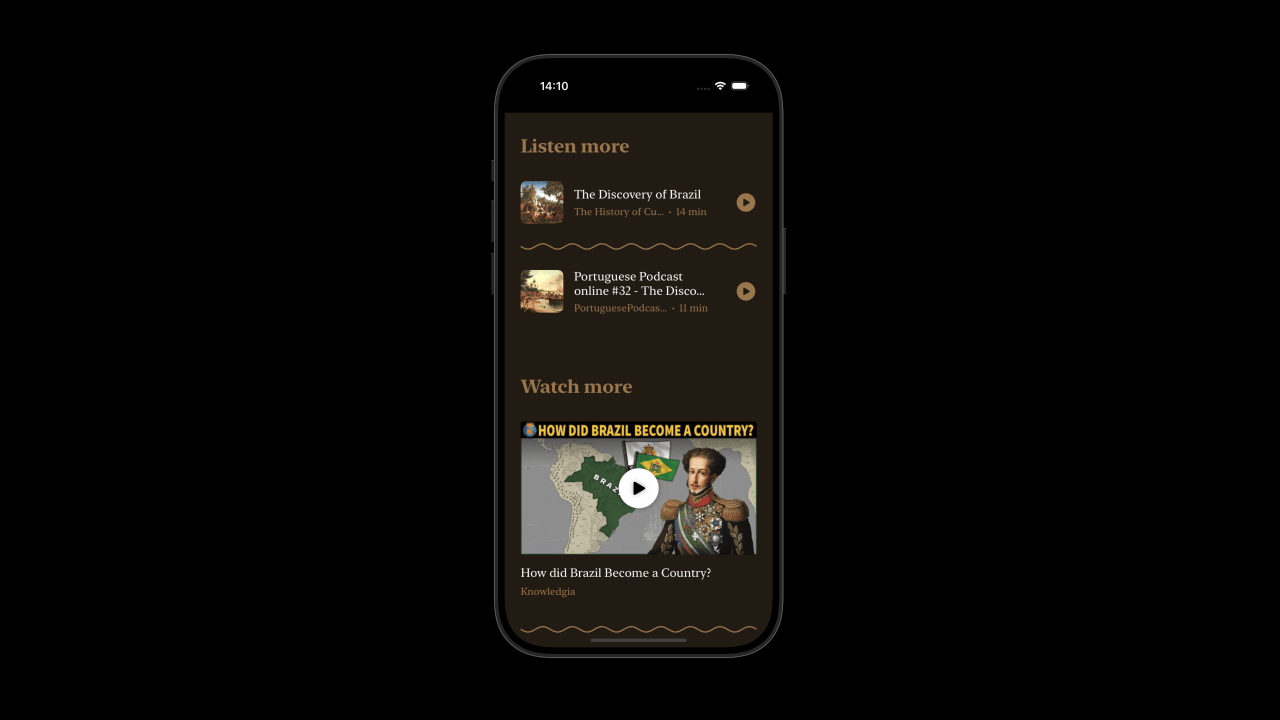
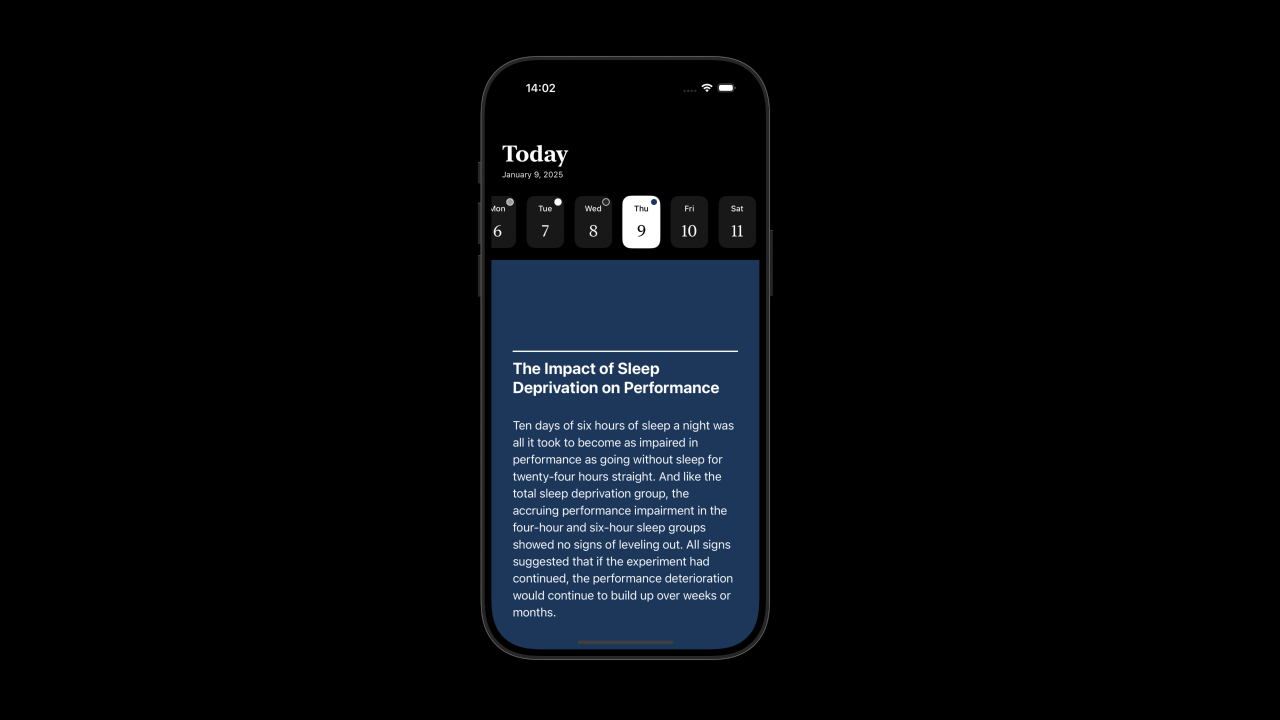
Last, I redesigned the home page to be much more fun to browse. I added a calendar view that has a small badge showing the color of the highlight.
How to deal with the accuracy of generated content?
This is a big topic. I don't want ChatGPT to generate a bunch of false information. I also prefer the idea of having mostly human-generated, not AI-generated, content and design. I want to get the most out of the AI, but in the background. ChatGPT should be mostly a curator rather than a generator.
I was already using ChatGPT in that way as it doesn't search the internet for content, but instead prepares the best API query. But as I was playing around with this, I found that the queries get a lot of results, but not every API search is equal in quality. The Wikipedia articles were mostly relevant but the results from Apple Podcasts and YouTube were often random. To fix this, after the API results are returned, I decided to implement a second ChatGPT call to do a relevance check. I have been playing with the prompt a lot and it currently looks like this:
let messages = [
["role": "system", "content": """
You are a relevance checking assistant for book highlights. As an assistant you need to match wikipedia articles and other content to the highlight and determine if it provides valuable context or a deeper understanding. The audience are smart, interested book readers who love to learn about the highlight and explore related interesting topics.
Consider an article relevant if it:
1. Directly relates to major themes, events, or concepts mentioned in the highlight
2. Provides helpful historical, cultural, or contextual background
3. Explains key terms, events, or phenomena mentioned in the highlight
4. Covers the broader historical period or movement discussed
5. Sparks interest in the reader about the subject of the highlight or a related subject even if it is not directly related
An article should be marked false only if:
1. It's completely unrelated to the highlight's content
2. It's so specific to a minor detail that it doesn't help understand the main point
3. It's so broad that it doesn't provide meaningful context for the specific topic, for example if the wikipedia article is about a super general topic like 'history' instead of 'the history of ancient greece'
4. The content sounds like a conspiracy theory, fake news, or other unfounded non-factual information.
Respond only with 'true' or 'false' for each article, one per line.
"""],
["role": "user", "content": prompt]
]The result of that is the following:
In this example, ChatGPT made the following corrections:
Highlight:
"Similarly, during the twentieth century, most philosophers, and many scientists, took the view that science is incapable of discovering anything about reality. Starting from empiricism, they drew the inevitable conclusion (which would nevertheless have horrified the early empiricists) that science cannot validly do more than predict the outcomes of observations, and that it should never purport to describe the reality that brings those outcomes about. This is known as instrumentalism."
🎙️ Episode 1: "What is Distinctive About Human Thought?" - ❌ Not relevant
🎙️ Episode 2: "Being and Event (The End of Reality)" - ✅ Relevant
🎙️ Episode 3: "Critique of Pure Reason" - ✅ Relevant
🎙️ Episode 4: "The End of Reality: Opening Lecture" - ✅ Relevant
🎙️ Episode 5: "Professor Huw Price Inaugural Lecture" - ❌ Not relevant
🎙️ Episode 6: "Beyond Phenomenology (The End of Reality)" - ✅ Relevant
🎙️ Episode 7: "The Art of War" - ❌ Not relevant
🎙️ Episode 8: "My Icon Girls | Brooke Shields" - ❌ Not relevant
🎙️ Episode 9: "My Icon Girls | Patty Pravo" - ❌ Not relevant
🎙️ Episode 10: "My Icon Girls | Lady Diana" - ❌ Not relevant
🎙️ Episode 11: "Philosophy" - ❌ Not relevant
🎙️ Episode 12: "Philosophy" - ❌ Not relevant
It correctly filtered out episodes that were too vague or broad. However, there is still lots of room for improvement. Mst episodes come from the same podcast. Also, many are not directly related to the topic discussed in the highlight. I do specifically show one of the worst examples here as most other highlights are about 'easier' subjects which results in better API returns.
I am trying to achieve what large content platforms have been working on for over a decade: trigger my interest in such a way that makes me dive into a rabbit hole of more content. But it's interesting how easily I can get close with a simple prompt.
The full highlight creation now looks like this:
- Find a random highlight and check if it has been used before
- Create a JSON file in a specific template and add the highlight
- Parse the highlight and send the book title to the Google Books API to get the full title, author, and book cover
- From the book cover, extract a set of colors that will be used in the templates
- Feed the highlight to ChatGPT which then does the following prompt:
let messages = [ ["role": "system", "content": "You are an AI assistant that enhances book highlights with additional context and information."], ["role": "user", "content": """ Given the following book highlight, generate additional information: Highlight: "\(highlight)" Book: "\(book)" Date: \(date) Provide a JSON response with the following fields: - title: THIS FIELD IS REQUIRED. A title for this highlight - geocode: THIS FIELD IS REQUIRED. Check the highlight for a relevant location. If a relevant location is mentioned, or in the larger context, a location would be helpful, add the latitude and longitude of the location. If not, respond with a latitude and longitude of 0 - location: the name of the location that you added. - tags: THIS FIELD IS REQUIRED. Create an array of maximum 3 relevant tags based on the highlight. - biggerPicture: THIS FIELD IS REQUIRED. Help the reader understand the highlight by placing it in a larger historical, societal, and or scientific context. Keep the content to one paragraph, keep it concise and easy to read. - relatedQuestions: THIS FIELD IS REQUIRED. Based on the highlight, imagine what follow up questions the reader may have. These could be about the context of the highlight, or events,terms,locations,people, etc mentioned in the highlight. Create one to three questions and keep them short and easy to read. - wikiQuery: THIS FIELD IS REQUIRED. based on this content, the wikipedia API will be called to return relevant articles. Make sure to extract the relevant content, topics, and other information to ensure that the Wikipedia API can return up to 3 of the most relevant related wikipedia articles. Keep it concise, only mention key terms, do not halucinate. - template: THIS FIELD IS REQUIRED. Choose the most appropriate template for displaying this highlight. Options are: "serious" for historical content, "minimal" for academic or scientific content, and "playful" for content that is philosophical or otherwise not directly academic, scientific, or historical. Base your choice on the tone and content of the highlight. """] ] - Then the Wikipedia, YouTube, and Apple Podcasts APIs are called
- Run the ChatGPT reference check mentioned above
-
Add all of the results to the JSON:
{ "date": "2024-12-27", "title": "Sugar cane production in Brazil", "highlight": "On 9 March 1500, a fleet of 13 ships set sail from Lisbon. This was the most grandiose of all expeditions so far. It was apparently destined for the East Indies and was under the command of Pedro Alvares Cabral, a nobleman scarcely more than 30 years old. The fleet, after passing the Cape Verde Islands, headed west, away from the African coast. On 21 April it sighted what would become Brazilian land. On that day a landing party went ashore briefly. On the following day the fleet anchored at Porto Seguro, on the coast of the present-day state of Bahia.", "book": "A Concise History of Brazil (Boris Fausto)", "location": "Porto Seguro", "geocode": { "latitude": -16.44442870592626, "longitude": -39.065503569895775, }, "tags": ["Historical Trade Practices", "Sugar Cane Production", "Colonial Brazil"], "biggerPicture": "Pedro Álvares Cabral’s 1500 expedition occurred during the Age of Exploration, when European powers sought new trade routes and territories. Portugal, empowered by the Treaty of Tordesillas (1494), aimed to explore lands within its designated zone. Cabral’s fleet, bound for the East Indies, accidentally veered west, leading to the discovery of Brazil. This marked the start of Portuguese colonization in South America, expanding Portugal’s empire and reinforcing its global influence.", "relatedQuestions": [ "What was Pedro Álvares Cabral?", "What is the history of Porto Seguro?" ], "wikiURL": [ "https://en.wikipedia.org/wiki/Porto_Seguro", "https://en.wikipedia.org/wiki/Discovery_of_Brazil", "https://en.wikipedia.org/wiki/Colonial_Brazil" ], "wikiQuery": "", "bookTitle": "A Concise History of Brazil", "author": "Boris Fausto", "coverImageURL": "https:\/\/books.google.com\/books\/content?id=IS0DBAAAQBAJ&printsec=frontcover&img=1&zoom=3&source=gbs_ap", "template": "serious", "podcastEpisodes": [ { "trackId": 1541765851, "trackName": "The Discovery of Brazil", "collectionName": "The History of Current Events", "description": "The official story is that Brazil was discovered by Pedro Álvares Cabral, a Portuguese sailor who while far out at sea on a voyage to India around the African continent spotted some seaweed and found what he believed to be a large island sitting in the Atlantic. However the French nobility claim to have discovered it 4 years earlier.", "artworkUrl600": "https://is1-ssl.mzstatic.com/image/thumb/Podcasts211/v4/15/82/34/15823450-9a24-dcc5-8faf-69dfb23eae92/mza_16669839286271819614.jpg/600x600bb.webp", "releaseDate": "2022-12-27T00:51:59Z", "trackTimeMillis": 840000, "episodeUrl": "https://api.spreaker.com/download/episode/9610552/twig_110_mastered.mp3" }, { "trackId": 1483478132, "trackName": "Portuguese Podcast online #32 - The Discovery of Brazil", "collectionName": "PortuguesePodcast.online", "description": "In this episode, we are going to learn a little about the discovery of Brazil and the use of the verbs SER, ESTAR and FICAR, all meaning “to be” in English.", "artworkUrl600": "https://is1-ssl.mzstatic.com/image/thumb/Podcasts112/v4/2d/f5/4c/2df54ceb-5fdc-f35d-2115-d7059b83a39e/mza_16320792719464631338.jpg/600x600bb.webp", "releaseDate": "2019-10-09T00:51:59Z", "trackTimeMillis": 660000, "episodeUrl": "https://api.spreaker.com/download/episode/9610552/twig_110_mastered.mp3" } ], "youtubeVideos": [ { "videoId": "rqT51lU1IJw", "title": "How did Brazil Become a Country?", "description": "How did Brazil Become a Country?", "thumbnailURL": "https://img.youtube.com/vi/rqT51lU1IJw/0.jpg", "channelTitle": "Knowledgia" }, { "videoId": "XaYcSBYgcK4", "title": "The Animated History of Brazil", "description": "Head to http://squarespace.com/suibhne for a free trial and when you’re ready to launch, use the offer code SUIBHNE to save 10% off your first purchase of a website or domain", "thumbnailURL": "https://img.youtube.com/vi/XaYcSBYgcK4/0.jpg", "channelTitle": "Suibhne" } ] }
How to notify the user every day in a non-intrusive way?
Although I love Readwise, after a couple of weeks, the daily email just became another email in my inbox. Notifications, emails, and other ways to activate users have mostly become irrelevant in my daily life.
I want to find a solution to provide a daily highlight in a way that I am actually happy to read it. The way to do that is by self-motivation, not by disrupting my life with a notification. Growing up, our family read a lot and our dinner table was always full of newspapers, magazines, and books. Whenever we have a couple of minutes to kill, it's easy to have a seat and read something. The books and magazines are always in the background but available when the time is right.
I want technology to play the same role in my life. A great example of this is this project I came across that displays the front page of the New York Times on a large e-ink display on the wall. It refreshes daily in the background without disrupting you.
E-ink displays are amazing for this but not everyone has a large e-ink tablet hanging on the wall. Another option from my daily life is the old never-dying iPad that is mostly used as a smart home hub. It is always lying around somewhere in the living room and it would be a great way to give me a friendly nudge that a new highlight is available at the right moment. Especially if it could look more like a home hub rather than a full tablet UI.

What's next?
Currently, the app's core concept is working but there are tons of little improvements to be made. The two main areas of improvement are the UI and the refinement of ChatGPT. I will continue to work on the prompts to ensure that the results are more relevant and to add new sources as well. I will also be exploring how I could use e-ink displays as a device to provide the daily content.
When I started this project, I did not expect to get such a great result in such little time, all thanks to ChatGPT and Claude.
